Orange, to open sourcowe narzędzie do analizy danych. Stworzone przez słowacki uniwersytet. Proste, łatwe, skuteczne. Nie jest to zastępstwo do analizy w Python, R czy narzędziach takich jak SAS Data Miner, ale alternatywa, która pozwala (1) – rozpocząć przygodę z Data Science. (2) – przeprowadzić szybkie analizy danych, przykładowo w działach marketingu czy sprzedaży. Przyjrzyjmy się mu bliżej.
Narzędzie można pobrać i zainstalować ze strony https://orange.biolab.si/
Jest ono również dostępne z poziomu oprogramowania Anaconda.
Po uruchomieniu, widzimy typowe, dla 'visual programming’ aplikację. Po lewej stronie różne 'klocki’, z których możemy korzystać, natomiast po prawej nasza przestrzeń robocza, gdzie budujemy swój workflow.

Wszystkie nasze klocki, składają się z 5 kategorii:
- Data – umożliwiają nam wczytanie danych z różnych źródeł oraz ich transformację
- Visualize – typowe dla analizy danych wykresy, takie jak dystrybucja, scatter plt, box plot, heat map itd
- Model – modele do uczenia z nadzorem, czyli drzewa decyzyjne, regresja, SVM, Random Forest, ale również klocki do zapisu naszego modelu, tak abyśmy mogli go później wykorzystać do predykcji w systemie produkcyjnym
- Evaluate – czyli Confusion Matrix, Lift Curve czy ROC
- Unsupervised – uczenie bez nadzoru, jak algorytm k-Means, MDS czy też PCA
A wszystkie 'zabawki’, które mamy do dyspozycji, wyglądają tak:
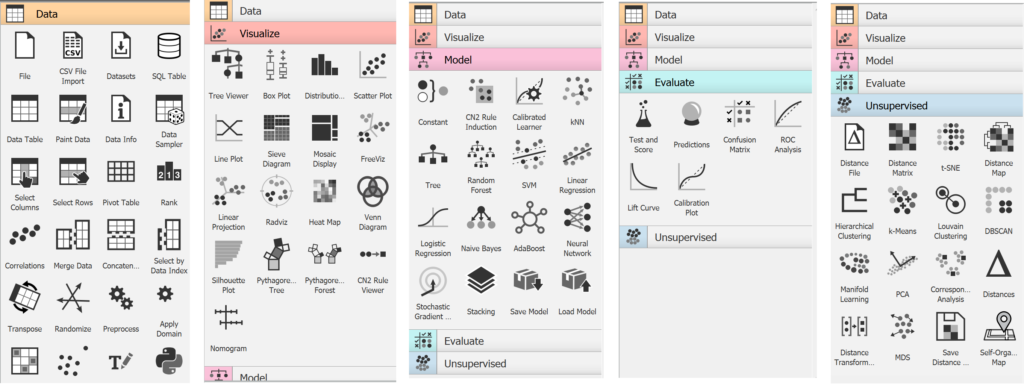
Jest tego sporo, i nie powstydziło by się tego zestawu, nie jedno komercyjne narzędzie.
Z ciekawych smaczków, mamy również narzędzie do generowania zbioru danych, w sposób wizualny:
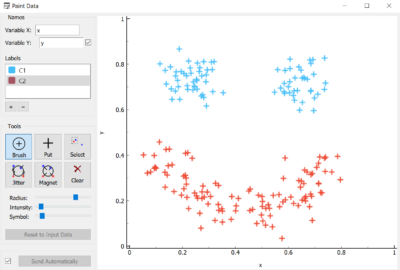
A w wyniku otrzymamy tabelę z danymi. Jest to bardzo wygodne przy eksperymentowaniu z różnymi technikami data science i analizy danych.
W dowolnym momencie, możemy również, podczepić do naszej pracy skrypty napisane w Python.
Orange data science & visualization, w akcji
Dokonajmy prostej analizy, klasycznego zbioru, z pasażerami statku Titanik, aby zobaczyć jak możemy użyć wszystkich tych elementów w praktyce.
- Dane pobierzemy za pomocą 'File’. Sam plik z danymi Titanik, możemy pobrać z adresu – http://analityk.edu.pl/wp-content/uploads/2020/02/titanic.csv
- Wybierzemy interesujące na kolumny, oraz oznaczymy kolumnę 'survived’, jako nasz target, za pomocą 'select columns’
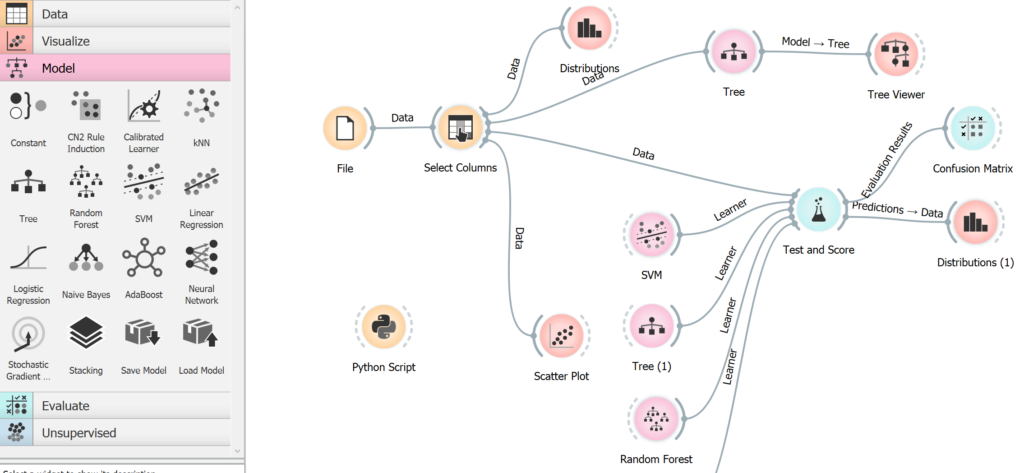
- Użyjemy algorytmów SVM, Decision Trees oraz Random Forest, które połaczymy do klocka 'Test and Score’
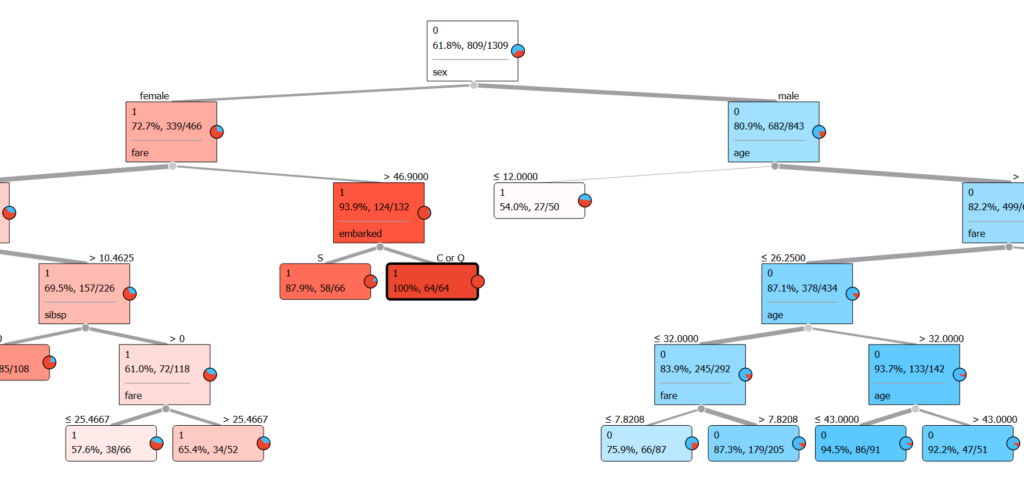
- Wyświetlimy drzewo decyzyjne za pomocą 'Tree Viewer’
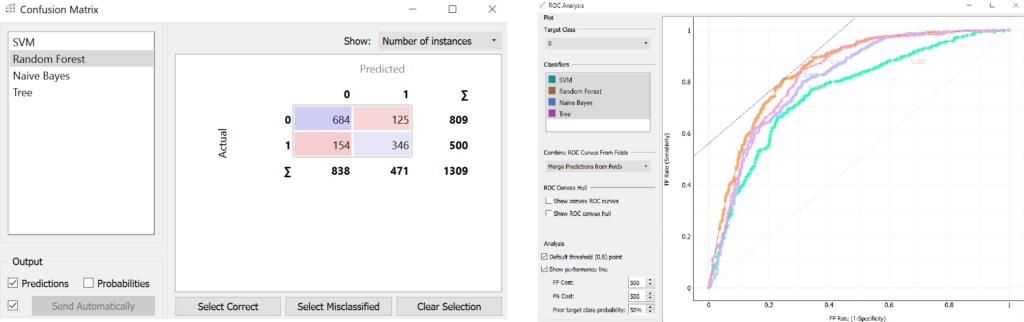
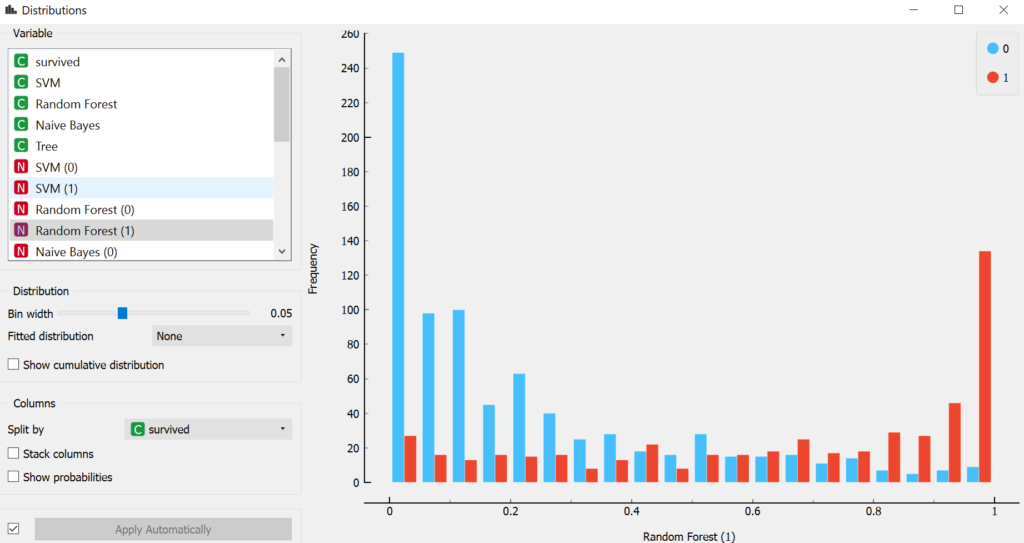
- A na końcu porównamy skuteczność algorytmów, za pomoca ROCa, Confusion Matrix oraz dystrybucji zgonów i przeżyć według przypisanych im prawdopodobieństw przeżycia.
- A sam model Random Forst, zapiszemy za pomocą 'Save Model’, tak abyśmy mogli go później użyć w potencjalnych programie, który byśmy pisali w Python.
Nic wielkiego. Prosta, szybka analiza.
A nasz workflow wygląda tak:

Widok naszego drzewa decyzyjnego:
Confusion Matrix oraz ROC
Dystrybucja pasażerów, którzy przeżyli i którzy zginęli według modelu Random Forest
Podsumowując
Orange Data Mining, działa szybko i przyjemnie. Nie wymaga on wiedzy eksperckiej aby zrobić podstawowe wizualizacje danych, czy też podstawowe model, jak np Drzewo decyzyjne. W konsekwencji ma również mnie opcji niż inne narzędzia jak Rapid Miner, KNIME czy SAS Data Miner. Ale czy to źle?
Nie. wręcz przeciwnie. Orange bardzo dobrze, adresuje konkretny obszar runku. Obszar, w którym ludzie potrzebują przeprowadzić szybkie analizy i nie potrzebują precyzji skalpela chirurgicznego. Za po potrzebują atrakcyjnych i zrozumiałych wizualizacji, a czas to pieniądz.
Na koniec końców, jest to dobre narzędzie, jeżeli planujemy rozpocząć swoją przygodę z Data Science. Nie przytłoczy, natomiast pozwoli zrozumieć ogólną ideę.







