Rozkład normalny, znany również jako rozkład Gaussa, jest najważniejszym i najbardziej pożądanym rozkładem z jakim mamy do czynienia w Data Science. W praktyce, będziemy sprawdzać czy zmienna ma rozkład normalny, często, i często będziemy zmienne do takiego rozkładu transformować. Poniżej zobaczymy jak sprawdzić czy zmienna ma rozkład normalny, za pomocą Python.
Co to jest rozkład normalny
Rozkład normalny, przyjmuje kształt przysłowiowego dzwonu i jest:
- Symetryczny
- średnia równa się medianie
- Asymptotyczny
- Jednomodalny, czyli posiadający tylko jedne maksimum
A wygląda tak:

Generowanie zbioru o rozkładnie zbliżonym do normalnego
Zanim porozmawiamy o sposobach badania normalności rozkładu, musimy wygenerować zmienną o podobnym rozkładzie.
Możemy to zrobić przy użyciu biblioteki Numpy, która wyposażona jest w funkcję random, do generowania liczb losowych. Dodatkowo, mamy opcję, aby generowane liczby, przyjmowały rozkład normalny.
Na początku, importujemy potrzebne biblioteki:
import numpy as np import seaborn as sns import matplotlib.pyplot as plt import pandas as pd
Następnie generujemy nasz zbiór, transformując go od razu do Pandas DataFrame:
normalVar = pd.DataFrame(np.random.normal(0,10,70)) normalVar.columns = ['value'] normalVar.head()
Zwróćmy uwagę, na użycie funkcji np.random.normal(0,10,70)
Pierwszy parametr, to środek naszego rozkładu. Drugi, to odchylenie standardowe, natomiast trzeci to liczebność generowanego zbioru.
W rezultacie otrzymujemy zbiór, które 5 pierwszych wierszy to:

Czyli liczebność będzie większa, tym nasz zbiór będzie w bardziej oczywisty sposób przypominać rozkład normalny. W powyższym przykładnie, celowo ustaliliśmy 70.
Sposoby testowania normalności rozkładu
Mamy dwa główne sposoby w jakie możemy ocenić nasz rozkład pod kątem jego normalności.
- Graficzny – czyli wizualizując rozkład zmiennej. Poniżej wykonany dwa popularne wykresy do tego służące.
- Statystyczny – wykonując jeden z wielu statystycznych testów, w wyniku których otrzymamy miedzy innymi wartość p, o której powiemy poniżej.
Graficzna ocena normalności rozkładu
Histogram
Jest to podstawowy sposób oceny normalności rozkładu. Tak zwany 'na oko’:
sns.distplot(normalVar) plt.show()
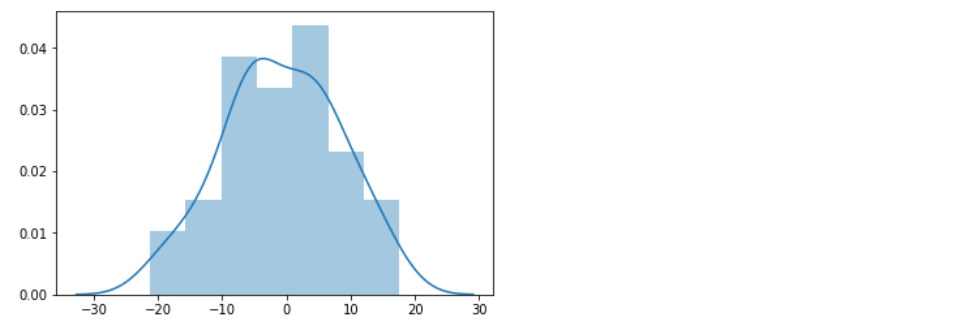
W faktu małej liczebności próbki, rozkład u każdego będzie wyglądać trochę inaczej.
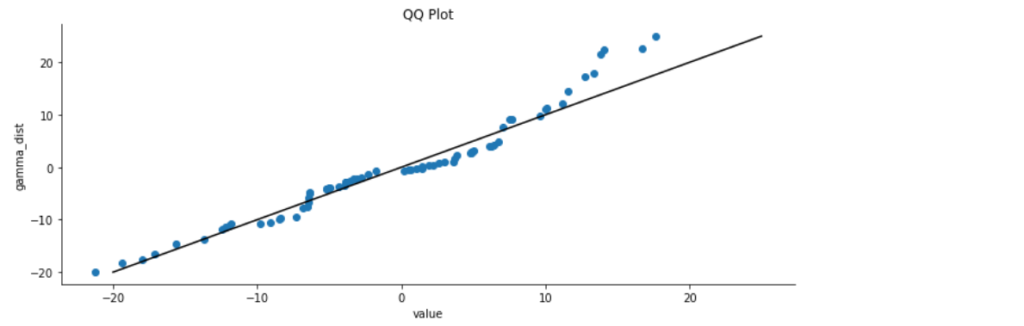
Q-Q Plot
Drugi, popularny typ wykresu, mający na celu ocenę rozkładu badanej zmiennej to Q-Q plot, znany również jako qq plot.
Jest to wykres, który pomaga nam zrozumieć czy zmienna pochodzi z konkretnego rozkładu. W naszym przykładzie, czym dokładniej punkty, ułożą się w linii prostej, bym rozkład jest bardziej zbliżony do normalnego.
Aby go wykonać, potrzebujemy zainstalować dodatkowy pakiet:
$ pip install seaborn-qqplot
import seaborn_qqplot as sqp
from scipy.stats import gamma
sqp.qqplot(normalVar,
x='value',
y=gamma,
aspect=2.5,
height = 4,
display_kws={"identity":True}
)
plt.title("QQ Plot")
plt.show()
Testy statystyczne
W statystyce, dostępnych jest wiele testów, mających za zadanie ocenić normalność rozkładu. Wiele z nic, zwraca 2 wartości. ’Statistic’ – wartość charakterystyczną dla danego testu, oraz wartość ’p’. My, skupimy się na tej drugiej,
Czym jest wartość ’p’?
Jest to wartość która pozwala nam z interpretować wyniki testu statystycznego w szybki sposób. W naszym przypadku, czy zmienna ma wartości pochodzące z rozkładu normalnego. I to jest nasza hipoteza zerowa.
W przypadku kiedy wartość p jest mniejsza/równa od 5 %, odrzucamy naszą hipotezę. Jeżeli wartość p jest większa od 5%, to prawdopodobnie zmienna ma wartości pochodzące z rozkładu normalnego.
Test D’Agostino–Pearson
Pierwszy test, który wykonamy, nazwany jest testem D’Agostino–Pearson i jest bardzo prosty do wykonania z pomocą biblioteki SciPy. Zakłada się przy nim, że próbka nie powinna mieć mniejszej liczebności niż 20.
from scipy.stats import normaltest
stats, p = normaltest(normalVar)
print(stats, p)
if p > 0.05:
print ("Rozkład wygląda na normalny")

Test Shapiro-Wilk
Drugi test, to chyba najpopularniejszy test normalności rozkładu – Shapiro-Wilka. Swoją popularność zawdzięcza również temu, że uważany jest często jako najlepszy test dla małych populacji (<50).
from scipy.stats import shapiro
stats, p = shapiro(normalVar)
print(stats,p)
if p > 0.05:
print ("Rozkład wygląda na normalny")

Podsumowanie
W statystyce mamy wiele różnych testów normalności rozkładu. Powyżej przedstawione sposoby, cieszą się popularnością, natomiast podstawowa znajomość Pythona i umiejętność interpretacji wyników, jest wystarczająca aby je szybko i łatwo wykonać.
Wszystkie kody źródłowe są dostępne w repozytorium GitHub, pod adresem: https://github.com/AnalitykEduPL/data-science







