
Jedną z podstawowych koncepcji, którą należy zrozumieć w Data Science jest typ uczenia. Mianowicie 2 podstawowe typy, które pojawiają się w każdej literaturze – uczenie z nadzorem oraz bez nadzoru.
Aby zrozumieć rodzaje uczenia maszynowego, najlepiej jest odwołać się do przykładu. Naszym będzie popularny problem biznesowy, jakim jest Fraud. Fraud, to dokonywane nadużyć, czyli przykładowo:
- Zgłaszanie fałszywych szkód do towarzystwa ubezpieczeniowego
- Dokonywanie transakcji płatniczych, kartą do której nie mamy autoryzacji
- Oszukiwanie operatora telekomunikacyjnego
Naszym zadaniem, jest zbudować algorytm, który będzie rozpoznawać transakcję, która zalicza się do Fraudu. Bardziej precyzyjnie – musimy zbudować algorytm, który na bieżąco będzie analizować wszystkie transakcje płatnicze i w momencie, w którym uzna, że dana transakcja jest wykonywana kradzioną kartą płatniczą, taką transakcję zablokuje.
Rodzaje uczenia maszynowego
Uczenie z nadzorem.
Pierwszy rodzaj uczenia, przypadek idealny, to taki w którym posiadamy zbiór danych historii różnych transakcji, z JASNĄ informacją, czy transakcja była Fraudem czy nie. Przykładowo:
| Numer karty | Kwota | Miejsce | Godzina | Fraud |
| 1357 | 30 | Gdańsk | 19.50 | nie |
| 1357 | 70 | Sopot | 11.00 | nie |
| 1357 | 290 | Zakopane | 23.45 | tak |
| 1357 | 300 | Zakopane | 17.30 | nie |
Na podstawie takiego zbiory danych, uczymy drzewo decyzyjne, regresję logistyczną, czy inny rodzaj algorytmu, klasyfikować transakcję jako Fraud lub nie.
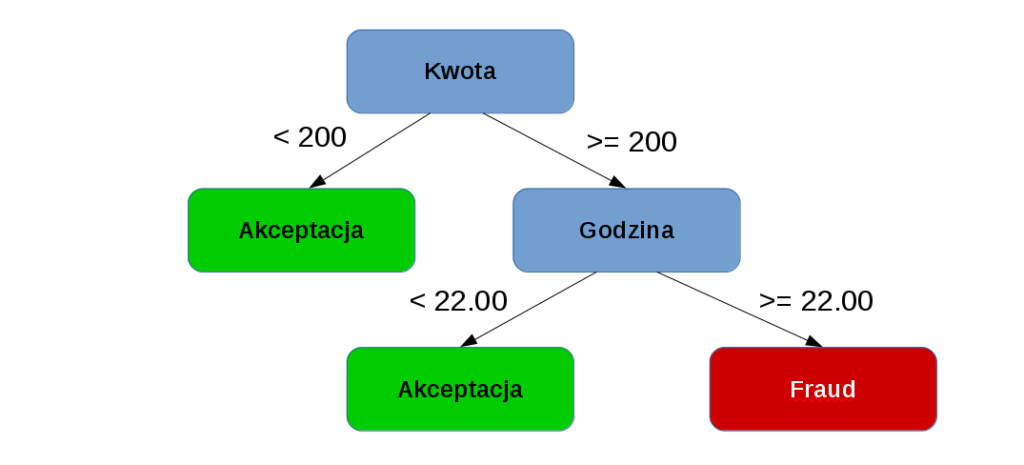
Jest to właśnie uczenie z nadzorem, którego najważniejszym aspektem, jest posiadanie ’Target value’, jakim jest informacja czy dana transakcja była Fraudem. Tego typu uczenia, daje często najlepsze rezultaty, czyli algorytm, który najlepiej radzi sobie z rozpoznaniem sytuacji.
W praktyce, posiadanie informacji czy transakcja była Fraudem czy nie, nie jest prosta do osiągnięcia, i specjaliści Data Science, muszą włożyć nie mały wysiłek, aby ją pozyskać, o ile to jest możliwe.
Możemy wyobrazić sobie, w której części transakcji fraudowych, nie udało się wyłapać. Czyli dokonano w przeszłości szeregu płatności kartą, które umknęły uwadze jako transakcje nie autoryzowane. Tym samym, nasz zbiór danych, będzie posiadać przekłamane informacje odnośnie 'Target Value’, lub takich informacji nie będzie posiadać.
Uczenie bez nadzoru.
W przypadku, kiedy nie mamy informacji o 'Target Value’, czyli w tym przypadku, czy transakcja była Fraudem czy też nie, mówimy o uczeniu – nienadzorowanym.
W tej sytuacji, zastosowanie drzew decyzyjnych czy też regresji, jest nieuzasadnione. W zamian, stosujemy inne podejścia, jak profilowanie zachowań, segmentację, czy też podejście które widzieliśmy w analizie koszyka zakupowego.
W naszym przypadku, możemy przeanalizować wszystkich klientów banku, i dokonać klasyfikacji / segmentacji, w zależności od wzorców zachować. W tym naszego klienta, z przykładu powyżej, o numerze karty 1357.
Jeżeli weźmiemy pod lupę wszystkich klientów banku, kwotę transakcji oraz godzinę jej wykonania, możemy dojść do przykładowego wniosku, że klienci, dzielą się na 3 główne grupy, w zależności od swojego wzorca zachowań.
- Grupa I – klienci, wykonujący transakcje o dużych kwotach, w godzinach wieczornych
- Grupa II– klienci, wykonujące transakcje o dużych kwotach w godzinach dziennych
- Grupa III – klienci, wykonujący transakcje o małych kwotach, w godzinach dziennych
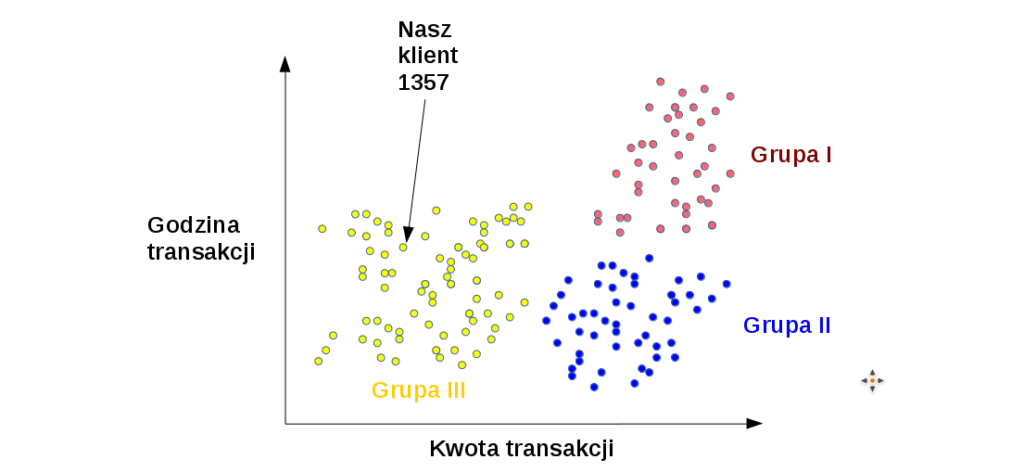
Nasz przykładowy klient, o numerze karty 1357, zdecydowanie zalicza się do grupy numer III. Klientów, którzy wykonują operacje na małych kwotach, w godzinach dziennych.
Tym samym spodziewamy się od niego zachowania, charakterystycznego dla tej grupy. Innymi słowy, w momencie kiedy na jego koncie zaobserwujemy transakcje, odpowiadające grupie II lub III, jak np transakcję na dużą kwotę w godzinach wieczornych, jest to sygnał o potencjalnych Fraudzie.
Takie samo zachowanie, dla klienta z grupy III, nie było by niczym podejrzanym.
W ten sposób, definiujemy model / algorytm, który został nauczony BEZ nadzoru, czyli BEZ wcześniejszej informacji na temat które operacje były Fraudem, a które nie. Operujemy na charakterystyce segmentu do którego zalicza się dany klient.
Podsumowując.
Obydwa podejścia do uczenia maszynowego, są praktykowane i mają swoje mocne strony. Aby efektywnie wykorzystywać korzyści Data Science, będziemy stosować obydwie metody uczenia. Z nadzorem i bez.
Również, nie jednokrotnie. będziemy je łączyć, aby uzyskać optymalne efekty. Nawiązując do naszego przykładu detekcji Fraudu, nic nie stoi na przeszkodzie, aby każda transakcja była oceniana pod kątem ryzyka nadużyć, przez obydwa modele, a finalna decyzja, była wynikiem połączenia tych dwóch ocen.
Jednocześnie, powyższe dwie metody, są podstawowymi metodami uczenia maszynowego w biznesie, jednak nie są jedyne w szerokim spektrum zastosowań AI, w którym znajdziemy przykładowo, uczenie przez wzmocnienie. O czym będziemy rozmawiać przy innej okazji.







