
Pandas, jest jednym z najbardziej rozbudowanych pakietów, do analizy danych, w Python. Scyzorykiem szwajcarskim. Możemy za jego pomocą, wczytywać dane, czyścić, modyfikować, a nawet analizować. Wszystko to co umożliwia nam SQL, Excel i dużo więcej. Po prostu kombajn. Poniżej zobaczymy, jak możemy zacząć używać go w praktyce. Zaczynajmy!
Praca analityka danych to w dużej mierze, przygotowywanie danych. Ich pozyskiwanie oraz obróbka. Tak, aby można było, na tej podstawie, dokonać ich analizy. I dokładnie to umożliwia Pandas. Jest to absolutnie genialna biblioteka, której popularność rośnie w oszałamiającym tempie i każda osoba, która ma do czynienia z analizą danych w Python, skorzysta na jej znajomości.
Pandas został zbudowany na bazie biblioteki NumPy, która często będzie używana razem z nim, dlatego warto się z nią zaznajomić. Wymagana jest również podstawowa znajomość języka Python. Pętle, listy, słowniki itd.
Poniżej:
- Instalacja oraz import Pandas
- Podstawowe typy danych w Pandas
- Tworzenie DataFrame
- Przeglądanie DataFrame
- Podstawowe operacje a DataFrame
- Filtrowanie DataFrame
- Sumowanie, grupowanie, oraz inne kalkulacje
- Łączenie DataFrame – SQL Join
- Wykresy
Instalacja oraz import Pandas
Pakiet Pandas, możemy zainstalować, za pomocą komendy pip:
$ pip install pandas
Następnie, go importujemy, za pomocą import. Przyjęło się, importować go jako pd
import pandas as pd
Podstawowe typy danych w Pandas
Series
Pierwszy typ danych to 'Series’. Dla analogii, możemy porównać ją do kolumny z Excela. Działa ona podobnie do listy w Python, jednak daje nam większe możliwości. Spójrzmy na kilka przykładów:
Zdefiniujmy zmienną typu Pandas Series, a następnie wykonajmy mnożenie razy 10:
a = pd.Series([-1,1,3,5,7]) a * 10

W łatwy sposób, możemy zmienić wartości na dodatnie, korzystając z funkcji abs():
a.abs()

Za pomocą funkcji describe(), uzyskać podstawowe statystyki:
a.describe()

Oraz zmienić nazwy indexów. Domyślenie są to liczby, zaczynające się od 0:
a.index = ['Pierwsza','Druga','Trzecia','Czwarta','Piąta'] a

DataFrame
Drugi typ danych, to DataFrame. O ile 'Series’ porównywaliśmy do kolumny, o tyle DataFrame, jest odpowiednikiem tabeli, czyli zestawieniem danych typu 'Series’. Jest to właśnie typ danych, z którego będziemy korzystać nieustannie.
Tworzenie DataFrame
Pandas, umożliwia nam tworzenie DataFrame na kilka sposóbów. Między innymi na podstawie listy, słownika czy też plików csv, xls, json.
Tworzenie DataFrame na bazie listy
Korzystamy tutaj z funkcji 'pd.DataFrame()’, która konwertuje naszą listę na typ danych Pandas:
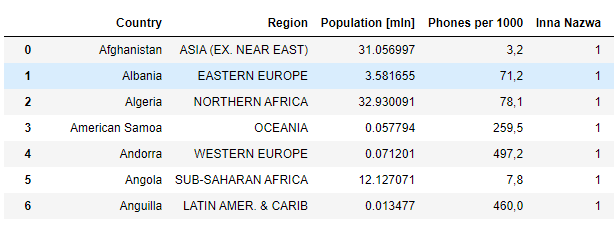
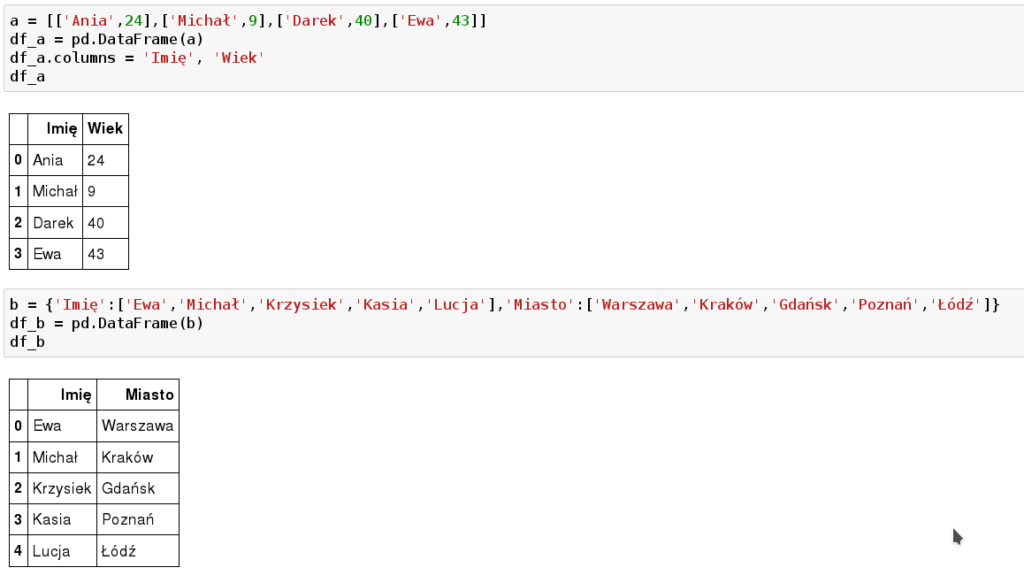
a = [['Ania',24],['Michał',9],['Darek',40],['Ewa',43]] df_a = pd.DataFrame(a) df_a.columns = 'Imię', 'Wiek' df_a

Tworzenie DataFrame na bazie słownika
Bardzo podobnie wygląda, utworzenie DataFrame na bazie słownika. Nie musimy jednak definiować nazw kolumn:
b = {'Imię':['Ewa','Michał','Krzysiek','Kasia','Lucja'],'Miasto':['Warszawa','Kraków','Gdańsk','Poznań','Łódź']}
df_b = pd.DataFrame(b)
df_b

Powyższe dwa DataFrame, będzie wykorzystywać później na potrzeby ćwiczeń. Teraz jednak, zajmijmy się utworzeniem trzeciego, na podstawie realnych danych.
Tworzenie DataFrame na bazie pliku CSV
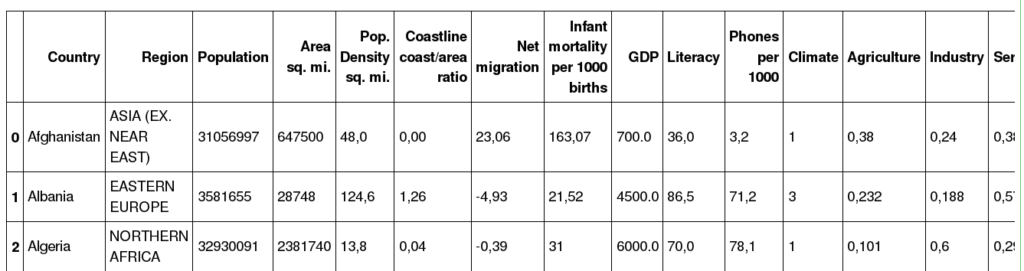
Standardową operacją, którą będziemy wykonywać, to tworzenie DataFrame na bazie danych ze zbiorów znajdujących się w xls, csv czy json. My, zaimportujemy dane dotyczące populacji, per kraj, per region. Dane do pobrania ze strony analityk.edu.pl, dokładnie pod adresem użytym poniżej, tak więc kody zadziałają u każdego:
df = pd.read_csv('http://analityk.edu.pl/wp-content/uploads/2020/01/Countries.csv')
Przeglądanie DataFrame
Skrzystamy tutaj z danych zaimportowanych z pliku csv, znajdujących się w DataFrame 'df’.
Mogli byśmy wyświetlić je wszystkie, jednak zajmie to dużo miejsca, zamiast tego wyświetlimy tylko 3 pierwsze wiersze. Wykonamy to w analogiczny sposób jak w przypadku list czy ndarray:
df[:3]
Możemy również, wyświetlić tylko konkretne kolumny:
df[['Country','Region']]

Lub, wyświetlić konkretne wiersze i kolumny, zdefiniowane za pomocą liczb, przy użyciu funkcji iloc():
df.iloc[0:3,0:3]

Niezwykle ważna jest również funkcja loc(). Umożliwia nam ona odniesienie się do konkretnych komórek, za pomocą numeru wiersza oraz nazwy kolumny.
df.loc[:3,['Country','Region','Population']]

Będziemy z tego często korzystać.
Podstawowe operacje na DataFrame
Poniżej przedstawimy szereg popularnych operacji. Zanim jednak do tego przejdziemy, utworzymy kopię naszego DataFrame, z wybranymi kolumnami. Dodatkowo, wyraźnie poinformujemy Pandas o tym że jest to kopia, i powinna mieć nowe miejsce w pamięci, za pomocą funkcji copy().
df_pop = df[['Country', 'Region', 'Population', 'Phones per 1000']].copy() df_pop
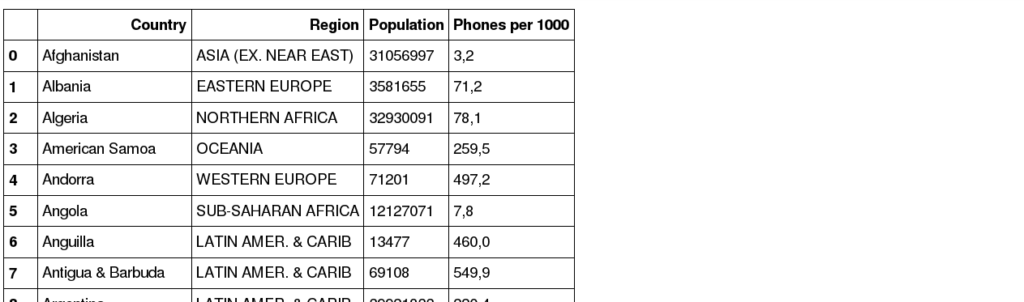
Jak widzimy, nowa zmienna 'df_pop’, zawiera tylko wskazane przez nas kolumny.
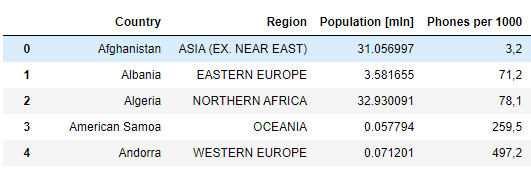
Bardzo wygodną rzeczą w Pandas, jest możliwość wykonywania operacji na całej kolumnie. W naszym przykładnie mamy kolumnę 'Population’. Warto jest zamienić ją na miliony, aby była bardziej czytelna, tak więc podzielić przez 1 000 000. Możemy to bardzo łatwo wykonać:
df_pop['Population'] /= 1000000
Z taką samą łatwością, możemy utworzyć nową kolumnę, i przypisać jej wartość:
df_pop['Nowa kolumna'] = 1
A następnie wyświetlić, naszą nową tabelę, za pomocą funkcji head(). Wyświetla ona 5 pierwszych wierszy, czyli jest równożnaczna z [:5].
df_pop.head()

Możemy zmienić również nazwę kolumny:
df_pop = df_pop.rename(columns={"Nowa Kolumna" : "Inna Nazwa"})
df_pop
Iteracje for loop
Pandas oferuje wiele możliwości przeglądania DataFrame w pętli for. Dwa popularne sposoby, to użycie do tego funkcji – iterrows(), oraz itertuples(). Pierwsza zwraca nam wiersz w liście, druga w tuple.
iterrows()
Spójrzmy na przykład użycia iterrows() w pętli for. Zadanie jest proste. Przeglądamy populację poszczególnych krajów, natomiast jeżeli populacja jest więkasza niż 100 milionów, to w nowej kolumnie, o nazwie 'Size’, umieszczamy tekst 'Big’.
for index, row in df_pop.iterrows():
if row['Population'] > 100:
df_pop.loc[index,'Size'] = 'Big'
print (row['Country'], df_pop.loc[index,'Size'])
Pętla zwraca index wiersza oraz zawartość wiersza. następnie, za pomocą funkcji loc(), znanej ze wcześniejszych przykładów, odwołujemy się do konkretnego indexu wiersza i dla niego w kolumnie 'Size’ przypisujemy odpowiednią wartość.
itertuples()
Druga funkcja, troszkę mniej popularna, za to szybsza to intertuples(). Spójrzmy na przykład zastosowania:
for row in df_pop.itertuples():
if row.Population > 200:
print(row.Index, row.Country, row.Population)
W przeciwieństwie do iterrows(), nie zwraca ona indexu, a trzeba się do niego odwołać poprzez row.Index.
Filtrowanie DataFrame w Pandas
Osoby znające SQL, przyzwyczajona są do częstych operacji
select X, Y, Z from table where warunek1 i warunek2
I to samo możemy łatwo osiągnąć za pomocą filtrowania, z użyciem mask w Pandas. Spójrzmy na praktykę:
df_pop.Population == 147.365352
W ten sposób tworzymy tak zwaną maskę, która dla wierszy o populacji podanej powyżej zwróci wartość True, a dla pozostałych False.
Następnie, taką maskę możemy wykorzystać do filtrowania całych wierszy z DataFrame, które nas interesują:
df_pop[df_pop.Population == 147.365352] df_pop[df_pop['Population'] == 147.365352]
I w rezultacie otrzymać, poszukiwane wiersze.

Możemy łączyć wyrażenia operatorem &, będący odpowienikiem 'and’, lub operatorm |, będący odpowiednikiem 'or’
df_pop[(df_pop['Population']>100) & (df_pop['Population']<150)]
Sumowanie, Grupowanie, oraz inne kalkulacje
Osoby przyzwyczajone do używania języka SQL, niewątpliwie, często używały operacji grupowania danych, w celu policzenia statystyk dla danej grupy. Odwołując się do naszego pliku, przykładowo – każdy wiersz odpowiada za jeden kraj, ale jaka jest populacja dla poszczególnych regionów. Pandas, dostarcza nam funkcji groupby, z pomocą której jest to łatwe i szybkie.
Na początku, policzmy statystyki dla całych kolumn:
print( df_pop['Population'].sum() ) print( df_pop['Population'].max() ) print( df_pop['Population'].min() ) print( df_pop['Population'].mean() )

Następnie wykonajmy kalkulacje dla poszczególnych regionów, używając funkcji groupby(’Region’)
print( df_pop.groupby('Region')['Population'].size() )
print( df_pop.groupby('Region')['Population'].sum() )
print( df_pop.groupby('Region')['Population'].min() )
print( df_pop.groupby('Region')['Population'].max() )
print( df_pop.groupby('Region')['Population'].mean() )

Każde wyliczenie – size, sum, min itd, znajduje się w osobnej tabeli, co jest mało wygodne.Możemy od razy utworzyć tabelę, zawierającą wszystkie na raz, za pomocą funkcji 'agg’. Spójrzmy:
df_pop.groupby('Region')['Population'].agg([min, max, sum])
I w wyniku otrzymać, jedną tablę z nowymi kolumnami:

Lub wykonać tą samą funkcję, wykorzystując słownik i nadając kolumnom nazwy własne:
df_pop.groupby('Region', as_index=False)['Population'].agg({"Suma":"sum", "Max":"max"})

Łączenie DataFrame – SQL Join
Prędzej czy później dojdziemy do konieczności połączenia dwóch tabel, za pomocą wspólnego klucza. Przykładowo, w jednej tabeli mamy osoby oraz ich wiek, w innej mamy osoby oraz miejscowość zamieszkania.
Teraz natomiast, potrzebujemy jednej tabeli ze wszystkimi tymi danymi. Imię jest kluczem wspólnym, po którym będziemy łączyć nasze zbiory.
W języku SQL, taka operacja, nazywana jest 'join-em’. W Pandas, mamy do dyspozycji funkcję 'merge’, która umożliwia nam połączenie tych tabel na 4 sposoby. Cztery, ponieważ w obydwu tabelach, część imion się pokrywa, natomiast występują również imiona, które się nie pokrywają, co rodzi pytanie, jak chcemy aby nasza finalna tabla wyglądała? Czy chcemy aby miała, tylko imiona wspólne, czy może imiona z pierwszej tabeli? drugiej? A może wszystkie?
Na potrzeby przykładów, wykorzystamy DataFrame, utworzone na początku artykułu:
1 – Uzyskanie części wspólnej
pd.merge(df_a, df_b, on='Imię')

2 – Wszystkie wiersze ze zbioru lewego, pasujące wiersze ze zbioru prawego
pd.merge(df_a, df_b, on='Imię', how='left')

3 – Wszystkie wiersze ze zbioru prawego, pasujące wiersze ze zbioru lewego
pd.merge(df_a, df_b, on='Imię', how='right')

4 – Wszystkie wiersze
pd.merge(df_a, df_b, on='Imię', how='outer')

Wykresy w Pandas
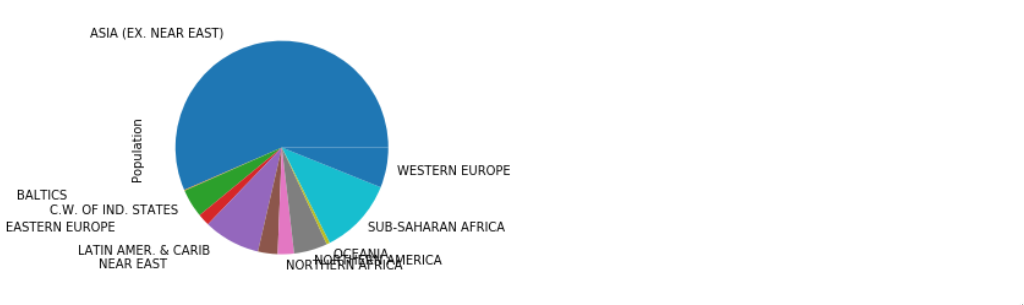
Ostatnią tematyką, o której wspomnimy, jest możliwość tworzenia wykresów. Pandas współpracuje z biblioteką Matplotlib i umożliwia szybkie generowanie wykresów. Tematykę wykresów w Pandas, omówimy w osobnym artykule, jednak zobaczymy prosty przykład, obrazujący zasady ich tworzenia.
import matplotlib.pyplot as plt
df_pop.groupby('Region')['Population'].sum().plot(kind='pie')
plt.show()
Podsumowując. Nie da się przejść obojętnie koło biblioteki Pandas. Może nasze dane wczytywać, modyfikować, przeglądać oraz analizować.
Zachęcamy do pobrania Jupyter Notebook, z kodami źródłowymi, oraz wykonania ich samodzielnie:
https://github.com/AnalitykEduPL/Najwazniejsze-biblioteki-Python






