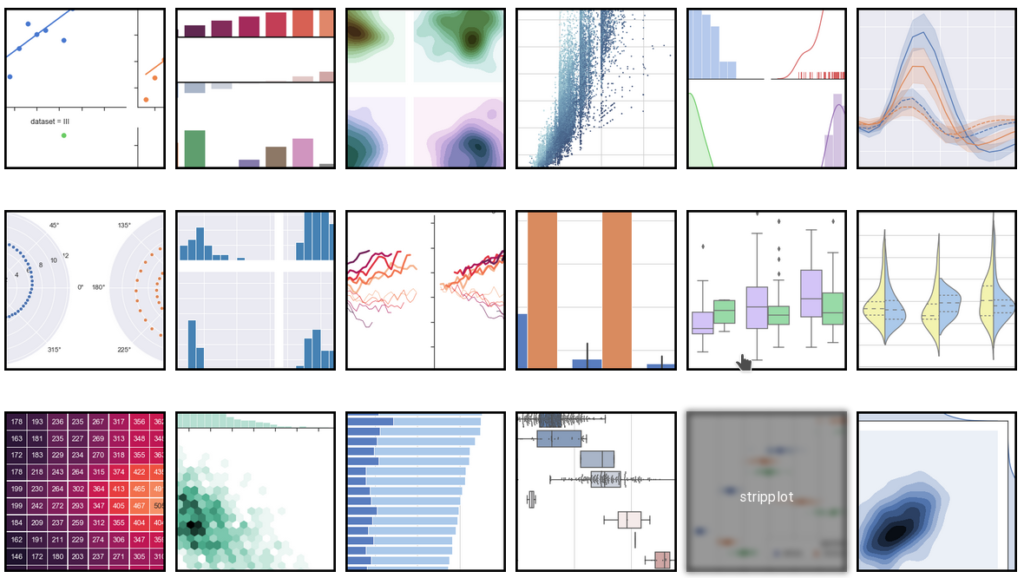
Seaborn, to zgrabna oraz efektywna biblioteka, pozwalająca na szybkie tworzenie atrakcyjnych wykresów, w Python. Została, zbudowana na bazie biblioteki Matplotlib, jednocześnie wzbogacona o dodatkowe typy wykresów. Poniżej zobaczymy, jak z niej korzystać w praktyce. Zaczynajmy!
Pełny opis jej możliwości, znajduje się na stronie Seaborn – tutaj. Dodatkowo, możemy tam znaleźć, dość dobrą dokumentację, lecz wymagającą odrobiną wprawy, aby się po niej poruszać.
My natomiast, skupimy się na najbardziej praktycznych i użytecznych typach wykresów, tak aby opanować pierwsze kroki z Seaborn.
Jupyter Notebook, z kodami, znajduje się w repozytorium GitHUB, pod adresem: https://github.com/AnalitykEduPL/Najwazniejsze-biblioteki-Python
Instalacja oraz import biblioteki Seaborn
Biblioteka Seaborn, powstała na bazie biblioteki matplotlib. Dodatkowo współpracuje z Pandas. Dlatego też, standardowym scenariuszem jest instalacja powyższych bibliotek
$ pip install seaborn
$ pip install pandas
Następnie importujemy importujemy powyższe biblioteki, za pomocą:
import seaborn as sns import matplotlib.pyplot as plt import pandas as pd
Zbiór danych
Na potrzeby nauki Seaborn, skorzystamy z dwóch zbiorów danych.
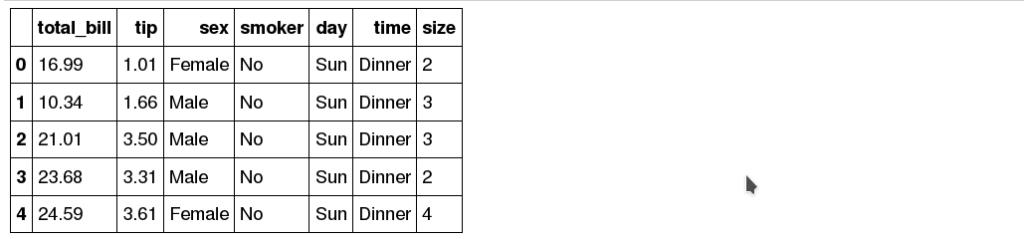
Pierwszy, dotyczy emisji CO2, w podziale na kraje, regiony, lata. Dostępny na stronie AnalitykEduPL. Drugi, jest zbiorem dołączanym do samej biblioteki Seaborn i zawiera dane na temat napiwków – wysokość rachunku, napiwek, dzień tygodnia, płeć oraz informacja, czy osoba była paląca.
1 – Emisja CO2
Pobierzmy oraz wyczyśćmy nasz zbiór danych.
df = pd.read_excel('http://analityk.edu.pl/wp-content/uploads/2020/01/World_Bank_CO2_cleaned.xlsx')
df.head()
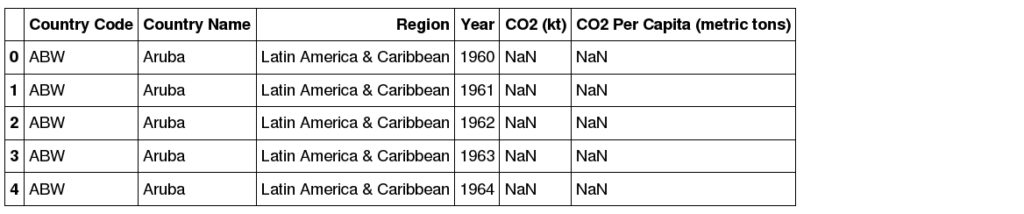
W rezultacie mamy zbiór danych, z krajem, regionem, rokiem, emisją CO2, oraz emisją CO2 na mieszkańca. Dane dla wczesnych lat, mogą być niekompletne, dlatego wyczyśćmy nasz zbiór, ograniczając go do lat > 1980, usuńmy wiersze z pustymi wartościami oraz przygotujmy zbiór pomocniczy, z danymi Polski
df= df[(~df['CO2 (kt)'].isnull()) & (~df['CO2 Per Capita (metric tons)'].isnull()) & (df['Year'] > 1980)] df_pl = df[df['Country Name']=='Poland']
2 – Napiwki
tips = sns.load_dataset("tips")
tips.head()
4 główne typy wykresów w Seaborn
Seaborn, posiada całkiem rozbudowany arsenał wykresów. Szczegóły dotyczące wszystkich z nich, znajdziemy na stronie produktu. My skupimy się na nauce pakietu oraz na 4 najczęściej stosowanych typach wykresów. Mianowicie
- Wykresy relacyjne
- Wykresy z kategoriami
- Wykresy z regresją
- Wykresy dystrybucji oraz korelacji
1 – Wykresy relacyjne
Prawdopodobnie, najpopularniejsze wykresy na świecie oraz pierwsze wykresy, które warto opanować. Możemy je generować za pomocą funkcji relplot(), która współpracuje z Pandas, tak więc bez problemu, przekażemy do niej zmiennę typu DataFrame, która jest podstawą pakietu Pandas.
Funkcja relplot()
Podstawowe parametry:
- data – wskazujemy zbiór danych
- x, y – wskazujemy dane, które mają być umieszczone na osi x oraz y
- hue – jeżeli chcemy, aby dane były kolorystycznie różne, w zależności od wartości zmiennej, to tutaj ją podajemy
- col, row – w ilu kolumnach i wierszach mają się wyświetlić wykresy
- kind – typ wykresu – czy liniowy, czy z punktami
- aspect – szerokość wykresu
Zobaczmy kilka przykładów:
Zobrazujmy generowane CO2, dla poszczególnych lat. Dla Polski oraz Niemiec. Dodatkowo, obydwa kraje, powinny być zróżnicowane kolorystycznie, natomiast sam wykres powinien być liniowy:
sns.set_context('paper')
sns.relplot(data=df[(df['Country Name'] == 'Poland') | (df['Country Name'] == 'Germany') ],
x="Year",
y="CO2 (kt)",
aspect=2.5,
kind='line',
hue='Country Name')
plt.show()
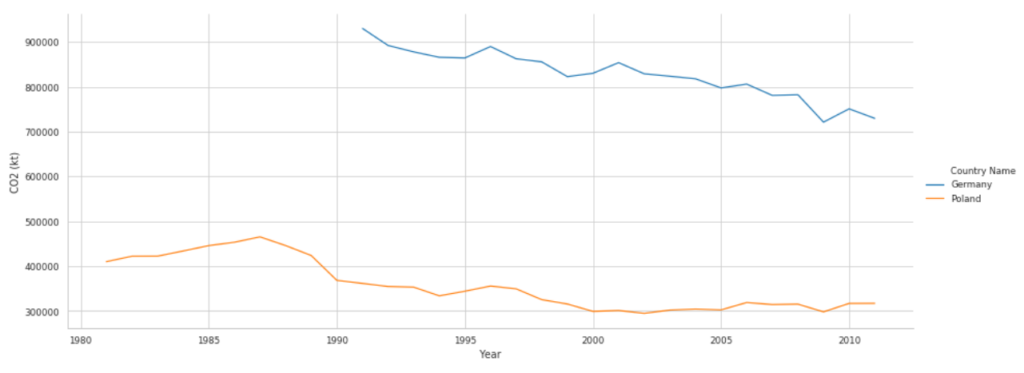
Funkcję set_context odpowiada za styl wykresu. Parametr 'paper’, daje nam bardzo delikatny wykres. Parametr 'poster’, wręcz przeciwnie.
W następnej kolejności, wygenerujmy wykresy, dla tych samych danych. Tym razem, Polskę i Niemcy, umieśćmy na osobnych wykresach oraz zmienimy rodzaj wykresu, z liniowego na punktowy.
sns.set_context('paper')
sns.relplot(data=df[(df['Country Name'] == 'Poland') | (df['Country Name'] == 'Germany') ],
x="Year",
y="CO2 Per Capita (metric tons)",
aspect=2,
kind='scatter',
col='Country Name')
plt.show()
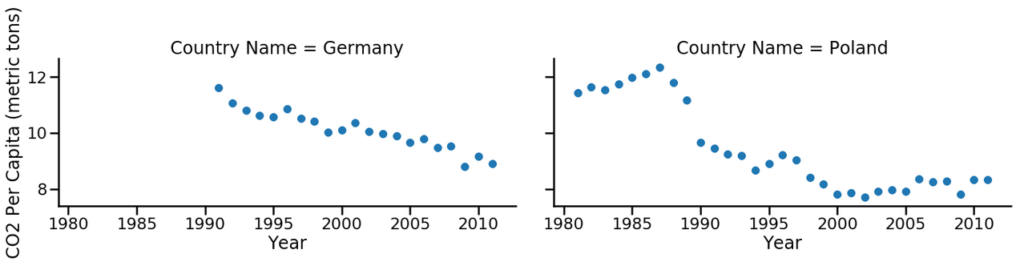
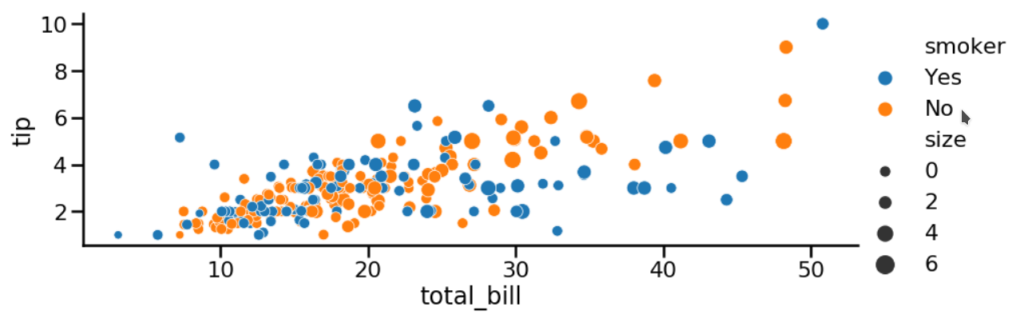
Wykorzystajmy nowo nabytą wiedzę, aby przeanalizować zbiór danych dotyczących napiwków. A dokładnie to zależność pomiędzy wysokością rachunku, a wysokością napiwku.
Dodatkowo, odróżnimy na wykresie dane, dotyczące osób palących oraz niepalących.
Ponownie używamy funkcji relplot, rodzaj wykresu – punktowy, rozmiar punktu, uzależniamy od zmiennej 'size’.
sns.set_context('poster')
sns.relplot(x="total_bill",
y="tip",
aspect=2.5,
data=tips,
size='size',
hue='smoker',
kind="scatter");
plt.show()
2 – Wykresy z kategoriami
Kolejne, popularne wykresy, to wykresy słupkowe różnego typu. Podstawową funkcją, którą powinniśmy poznać, jest 'catplot()’. Nazwa, od category plot.
Podobnie, jak w przypadku funkcji 'relplot()’, mamy kilka rodzajów wykresów słupkowych. Count, bar, box itd. Zobaczmy jak wyglądają.
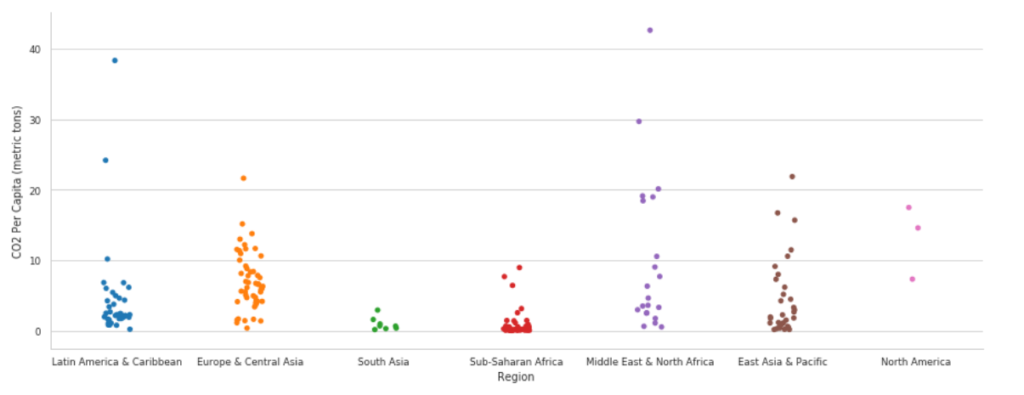
Zaczniemy od wykresu domyślnego, obrazującego wytworzone CO2 na osobę per region:
sns.catplot(x="Region",
y="CO2 Per Capita (metric tons)",
data=df[df['Year']==2010],
aspect=2.5)
plt.show()
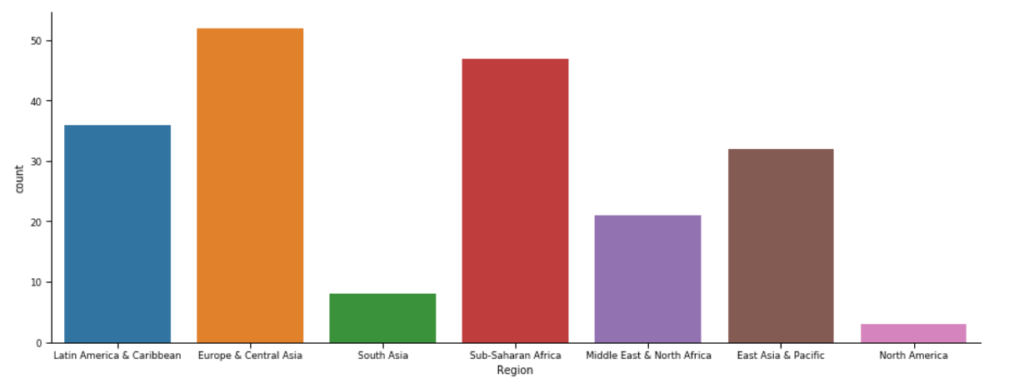
Następnie, najpopularniejszy wykres słupkowy, obrazujący ilość krajów w regionie. Użyjemy parametru kind, o wartości 'count’.
sns.set_context('paper')
sns.catplot(x="Region",
data=df[df['Year']==2010],
aspect=2.5,
kind='count')
plt.show()
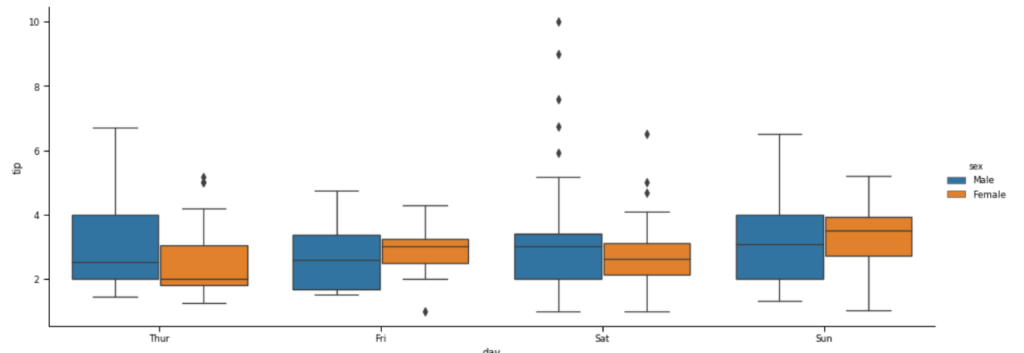
Box plot, pokazujący dane na temat CO2 na osobę, medianę, max oraz min:
tips = sns.load_dataset("tips")
sns.catplot(x="day",
y="tip",
aspect=2.5,
data=tips,
kind='box',
hue='sex')
plt.show()
Bar plot, tym razem, dla danych, dotyczących napiwków:
sns.set_context('paper')
tips = sns.load_dataset("tips")
sns.catplot(x="day",
y="tip",
aspect=1,
data=tips,
kind='bar')
plt.show()

3 – Regresja
Kolejny popularny rodzaj wykresu. podobny do wykresu relacyjnego, z tą różnicą, że mamy na nim zaznaczony trend. Podstawowa funkcja, która przychodzi nam z pomocą to 'lmplot()’.
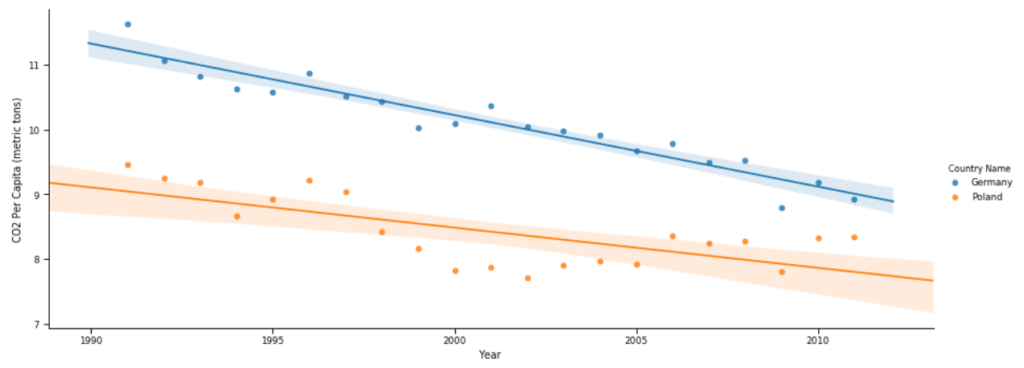
Zobaczmy jaki jest trend, jeżeli chodzi o spadek ilości generowanego CO2:
sns.set_context('paper')
sns.lmplot(data=df[((df['Country Name'] == 'Poland') | (df['Country Name'] == 'Germany')) & (df['Year']>1990)],
x="Year",
y="CO2 Per Capita (metric tons)",
aspect=2.5,
hue='Country Name')
plt.show()
4 – Dystrybucja
Każdy analityk danych, korzysta z wykresów pokazujących dystrybucję zmiennej. Zwanego również histogramem.
Distplot()
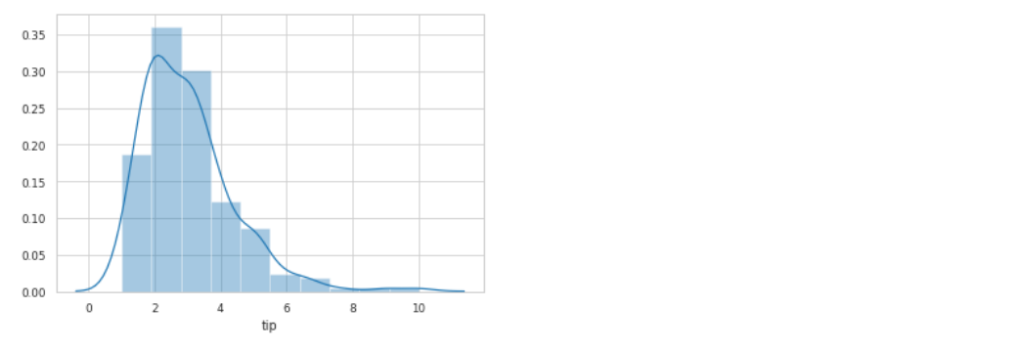
Histogram możemy w banalny sposób, wygenerować, przekazując do funkcji 'distplot()’, zmienną, którą chcemy przeanalizować. Dodatkowo, możemy skorzystać, ze zmiennej 'bins’ i doprecyzować, ilość zakresów jaki chcemy wyświetlić:
tips = sns.load_dataset("tips")
sns.distplot(tips['tip'], bins=10)
plt.show()
Powiedzmy, że chcemy wyświetlić osobny histogram dla kobiet, i osobny dla mężczyzn, ale na jednym wykresie.
W tym przypadku, wywołamy funkcję distplot, dwukrotnie, a dopiero później plt.show()
tips = sns.load_dataset("tips")
sns.distplot(tips[tips['sex']=='Male']['tip'], bins=10, kde_kws={"label": "Male"})
sns.distplot(tips[tips['sex']=='Female']['tip'], bins=10, kde_kws={"label": "Female"})
plt.show()

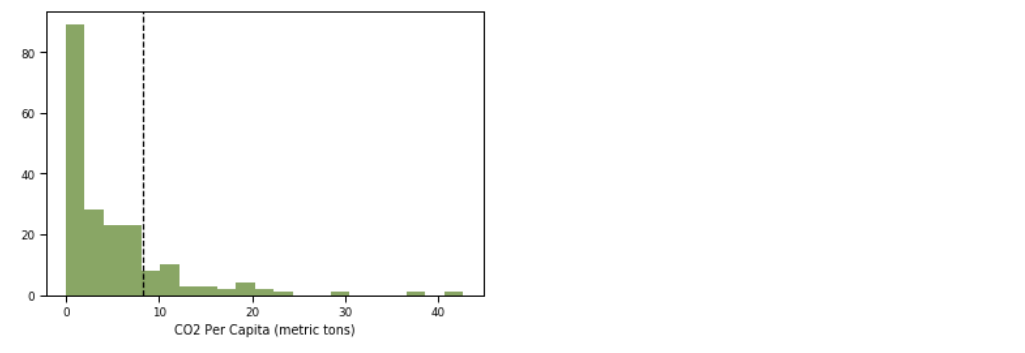
I na końcu, zobrazujmy, jeszcze raz, zużycie CO2 na osobę, tym razem, zaznaczając położeni Polski. Polska ma zużycie na poziomie 8.3:
sns.distplot(df[df['Year']==2010]['CO2 Per Capita (metric tons)'],
kde=False
);
plt.axvline(8.3,
color="k",
linestyle="--");
plt.show()
Podsumowując. Ciężko odmówić bibliotece Matplotlib funkcjonalności, jednak Seaborn dba nie tylko o funkcje, ale również o estetykę. Tym samym jest coraz częściej wybieraną biblioteką przy analizie danych, a domyślnie wygenerowane wykresy, są wystarczająco eleganckie, aby bez 'wstydu’, można było przesłać je dalej.
Zapraszamy do pobrania Jupyter Notebook, z repozytoriów GitHUB, a następnie powtórzenia powyższych wykresów, we własnym zakresie.






