
Niezależnie czy interesuje nasz web scraping czy też komunikacja z API różnych serwisów, potrzebujemy biblioteki, która umożliwi nam wykonywanie zapytań HTTP. Biblioteka Requests, nie jest jedyną, jednak stała się tak popularna, że została uznawana przez wielu ludzi, za standard. Poniżej zobaczmy jak możemy ją wykorzystywać w praktyce.
Podstawy zapytań HTTP
Dwie, najpopularniejsze metody używane do obsługi zapytań HTTP, to GET oraz POST.
GET
Za każdym razem, gdy nasza przeglądarka, pobiera strony internetowe, używa do tego metody GET. Jest to informacja dla serwera, który tę stronę hostuje, że należy zwrócić dla naszej przeglądarki zawartość strony. Powiedzmy, że chcemy pobrać zawartość fikcyjnej strony www.lokalizacje-miast.com. Strona zawiera współrzędne geograficzne miast.
Czyli nasza przeglądarka, wysyła zapytanie podobne do poniższego:
GET https://www.likalizacje-miast.com
Po czym serwer, który tę stronę przechowuje, wie że przeglądarka chce pobrać jej zawartość.
Czasami, serwer oczekuje, że przeglądarka, przekaże dodatkowe parametry, które pozwolą mu doprecyzować co dokładnie ma dla niej zwrócić. Jak np nazwę miasta, dzięki wie, które współrzędne ma dokładnie zwrócić. Czyli nasza przeglądarka wysyła, zapytanie w stylu:
GET https://www.likalizacje-miast.com miasto=Chicago
Czasami, aby pobrać zawartość strony, należy podać login i hasło
GET https://www.likalizacje-miast.com miasto=Chicago auth=Login+hasło
POST
Drugą, najpopularniejsza metodą, do wykonywania zapytań HTTP jest POST. O ile GET było żądaniem pobrania treści, o tyle POST służy nam do jej przesyłania. Czyli wykorzystujemy wtedy, kiedy chcemy przesłać informację na serwer.
Z przykładem zastosowania POST mamy do czynienia, w momencie kiedy uzupełniamy formularze na stronach internetowych. Przeglądarka, zbiera, wpisane przez nas dane i wysyła rządzenia POST. Serwis, widząc zapytanie POST, jest przygotowany aby zawarte w nim dane czytać, i np zapisać w bazie danych. Przykładowo:
POST https://formlularz.com imię=’Jan’ nazwisko=’Kowalski’
Instalacja oraz import biblioteki Requests
Bibliotekę zainstalujemy bez problemu, za pomocą pip:
$ pip install requests
i równie bez problemu ją zaimportujemy:
import requests
Proste wykorzystanie funkcji GET
Wykorzystajmy nasza bibliotekę, aby pobrać zawartość strony analityk.
req = requests.get("https://analityk.edu.pl")
req.status_code
>> 200
Wykorzystujemy do tego celu, funkcję GET. Status_code, zwraca nam informację czy operacja się powiodła. Kod o wartości 200, oznacza, że tak. W innym przypadku, mamy do czynienia z błędem. Wartość 404, jest dobrze znaną nam wartością, mówiącą o tym, że strona nie istnieje.
Następnie, możemy wykorzystać kolejne funkcje, aby obejrzeć nagłówek oraz treść strony:
req.headers

req.text

Przykład użycia funkcji GET
Jako prosty przykład wykorzystania funkcji get, wykorzystamy serwis dictionary.com. Serwis ten, zwraca definicję, podanego przez nas słowa. Np. Jeżeli wykonamy operację GET na adres https://www.dictionary.com/browse/computer, to w odpowiedzi dostaniemy stronę html, wraz z definicją słowa computer.
Możemy również wpisać ten adres w swojej przeglądarce, i zobaczyć rezultat. My zrobimy to poniżej w Python:
szukaneSłowo = 'computer'
res = requests.get('https://www.dictionary.com/browse/' + szukaneSłowo)
print(res.url)
print(res.text)
W odpowiedzi otrzymamy:

Oprócz definicji słowa computer, jest tam również wiele znaczników HTML i zbędnej treści. Na potrzeby demonstracji, skorzystamy z jeszcze jednej biblioteki, która ułatwi nam wyciągnięcie tego co nas interesuje. Samą bibliotekę, będziemy omawiać przy innej okazji, tak więc ominiemy tutaj szczegóły:
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,'html.parser')
desc = soup.find_all("meta")
for tag in soup.find_all("meta"):
if tag.get("name") == "description":
print(tag.get("content"))
A w odpowiedzi, otrzymamy:

Dodatkowe parametry
Bardzo szybko, natrafimy na konieczność przekazania dodatkowych parametrów. Czy to nazwy miasta, z początku artykułu, czy to klucza API.
Na potrzeby ćwiczeń, skorzystamy z serwisu https://httpbin.org/, który został stworzony na potrzeby przećwiczenie praktycznie wszystkich operacji, jakie możemy wykonać przy protokole HTTP. Opis jego działania, znajduje się na jego stronie.
Dodatkowe, parametry, możemy przekazać w formie słownika do funkcji GET. Spójrzmy na poniższy przykład:
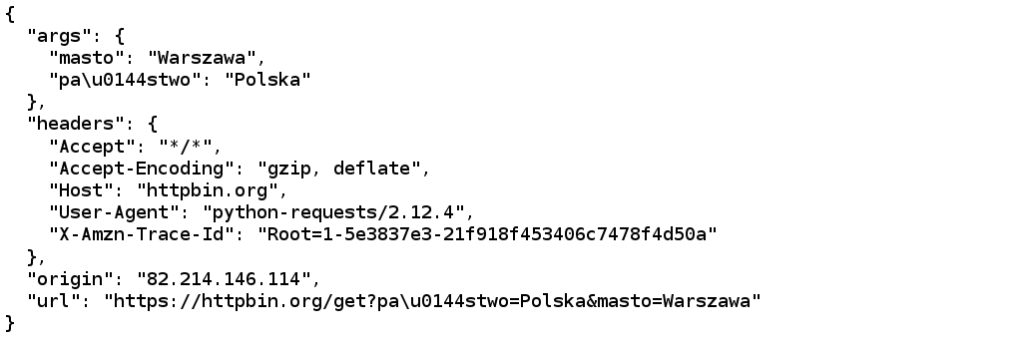
parameters = { 'masto' : 'Warszawa', 'państwo' : 'Polska' }
r = requests.get('https://httpbin.org/get', params=parameters)
print (r.text)
A, w wyniku, serwis httpbin, zwróci nam:
Autoryzacja
Oprócz przekazywania dodatkowych parametrów, możemy mieć do czynienia z koniecznością autoryzacji połączenia. Czasami odbędzie się to poprzez przekazanie klucza API, w dodatkowych parametrach, a czasami, np tak jak w przypadku serwisu gitHub, loginu oraz hasła.
Methoda GET umożliwia nam zgrabne rozwiązanie tego problemu poprzez użycia parametru auth=(login, hasło). Spójrzmy:
res = requests.get('https://api.github.com/user', auth=('login', 'haslo'))
print(res.text)
W odpowiedzi dostaniemy:
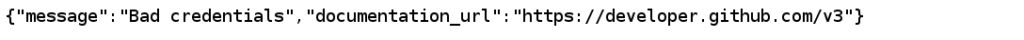
Jednak, w momencie kiedy podamy prawdziwy login i prawidłowe hasło, komunikacja zakończy się sukcesem.
POST
Kolejną funkcją, którą warto poznać jest POST. Powoduje ona przesłanie danych, na wskazanych adres. Działa podobnie jak funkcja GET w przypadku podawania dodatkowych parametrów, jednak zamiast 'params’, używamy zmiennej o nazwie 'data’.
body_data = {"Wiek": 30, "Osoba": "Jak Kowalski"}
r = requests.post('https://httpbin.org/post', data=body_data)
print(r.text)

Podsumowując
Requests, to efektywna biblioteka, która ułatwia nam komunikację HTTP, do celów web scrapingu oraz komunikacji z API opartym o HTTP.
Natomiast wszystkie wyżej wymienione kody źródłowe, znajdziemy w repozytorium GitHUB – https://github.com/AnalitykEduPL/Najwazniejsze-biblioteki-Python






