
Analityk danych, data miner, machine learning expert, data scientist, AI expert, data engineer, BI expert i tak dalej….. to wszystko są przyszłościowe i dobrze płatne zawody. Powody są proste. danych jest coraz więcej, a rozwój komputerów dostarcza nam coraz to nowych sposobów, ich przetwarzania i w rezultacie osiągania korzyści. Tak więc jak zostać jednym z nich?
Na początku należy sobie uświadomić, że zawody są pokrewne, ale nie takie same. Podobnie jak w przypadku programistów, gdzie mamy osoby specjalizujące się we front end dewelopmencie, back end dewelopmencie, programowaniu systemów rozproszonych itd.
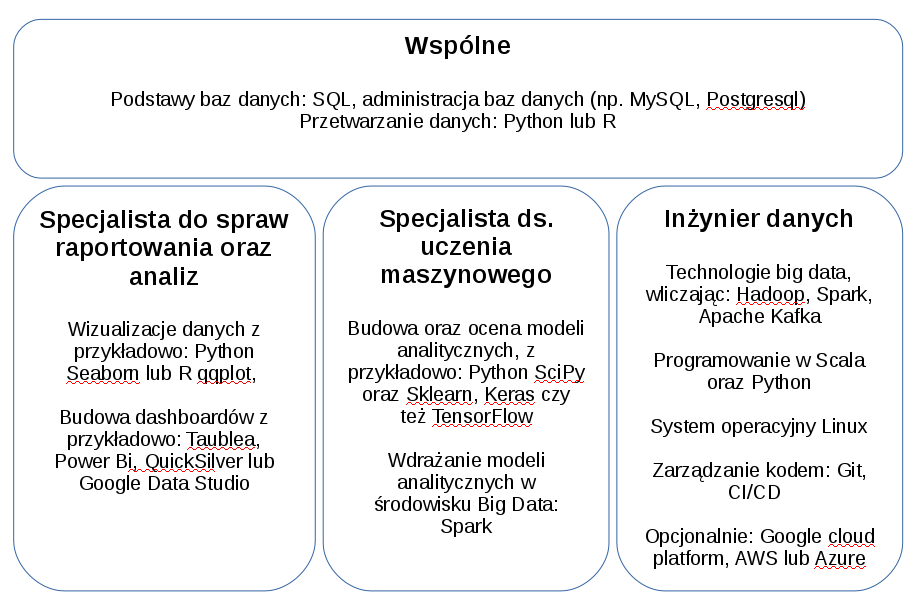
Przypadku Data Science oraz Sztucznej inteligencji, możemy podzielić nasze specjalizacje na 3 główne kierunki, natomiast droga do zostania jednym z nich jest trochę inna, i wymagane są po części inne kompetencje. Najważniejszą wspólną kompetencją jest język Python, który możemy nauczyć się na profesjonalnym kursie – Kurs Python, od podstaw do zaawansowanego zastosowania w firmie.
3 główne role w Data Science
1. Specjalista do spraw raportowania oraz analiz
Często nazywane Business Intelligence Expert lub SQL programmer.
Osoba na tym stanowisku używa istniejących w firmie danych, aby przygotować wartościowe, dla kierownictwa, raporty w formie tabel lub wykresów. Mogą to być wykresy statyczne lub interaktywne dashboardy.
Podstawowymi narzędziami są często SQL, Python, R oraz narzędzia do wizualizacji danych – od Excel po Tableau czy Power BI. Należy również efektywnie korzystać z baz danych, takich jak MySQL, Postgres, Oracle czy czasami Hadoop.
Gdybyśmy to stanowisko porównali do programowania, nazwali byśmy je Front End Developer, gdyż jest to często praca 'końcowa’, ta która jest najbardziej widoczna dla innych działów w firmie.
Ważne są umiejętności analityczne i umiejętność 'wyciągania’ wniosków z danych. Olbrzymie znaczenie odgrywa, zdolność zrozumienia wymagań działów takich jak marketing, sprzedaż, finanse itd, aby nasza praca była dla nich jak najbardziej korzystna. Nie jest wymagane bycie matematykiem, a raczej osobą 'twardo stąpającą po ziemi’, z dociekliwością.
2. Specjalista ds. uczenia maszynowego

Stanowisko często nazywane Machine Learning expert, Data Miner, a czasami AI engineer lub AI expert
Osoby na tych stanowiskach, odpowiadają za przygotowywanie i wdrażanie algorytmów, które dokonują predykcji, klasyfikacji czy też identyfikacji zdarzeń. W przeciwieństwie do specjalisty do spraw raportowania oraz analiz, muszą mieć wiedzę i umiejętności z zakresu algorytmów takich jak drzewa decyzyjne, regresja, sieci neuronowe, SVM itd.
Rola jest o wiele bardziej związana z matematyką, niż poprzednia, i umysł ścisły jest tutaj wymagany.
Nie każdy się w tym odnajdzie. Należy lubić matematykę i być biegłym w statystyce. Porównując do programisty, jest to rola pośrednia, pomiędzy front end development and back end development. Wymagania odnośnie modeli które będziemy budować, uzgadniamy z działem biznesowym. Z nim również prowadzimy jego testy, jednak bardzo dużo czasu poświęcimy na samodzielną pracę z danymi oraz analizując wyniki licznych algorytmów.
Narzędzia takie jak Python, R, SQL, ale również często Spark, są podstawą pracy osób na tych stanowiskach. Często również, pojawiają się rozwiązania komercyjne, takie jak SAS Miner czy IBM Cognos.
3. Inżynier danych

Stanowisko, nazywane często Data Engineer oraz Big Data Engineer.
Jest to osoba biegła w przetwarzaniu danych, która sprawia, że dane pojawiające się w firmie, są czyszczone, filtrowane, agregowane i umieszczane w bazach danych, w taki sposób aby wcześniej opisane role, mogły z nich opierać swoją pracę.
Należy rozumieć, konstrukcję hurtowni danych, oraz tematy Big Data, które często wiążą się z Hadoopem oraz Spark. Głównymi językami programowania, w tym obszarze, są Python oraz Scala.
W porównaniu do pracy programisty, jest to back end development, który nie wymaga od nas znajomości matematyki. Interakcja z działami biznesowymi jest również ograniczona. Trzeba jednak, być sprawnym programistą, który umie optymalizować przetwarzanie danych.
Ze względu na popularyzację rozwiązań chmurowych, coraz częściej wymagana jest znajomość specyfiki przetwarzania danych na platformach takich jak Azure, AWS czy GCP.
W porównaniu do wcześniejszych dwóch stanowisk, o wiele bardziej pomocne mogą się okazać certyfikaty, takie jak Google Data Engineer.
Wymagane kompetencje w pigułce
Poniżej, podsumowanie najważniejszych kompetencji, które warto posiadać. Nie jest to lista zamknięta i 'wykuta w kamieniu’. Liczba technologii używanych w analizie danych jest bardzo szeroka, i nie raz będziemy sięgać po inne rozwiązania.
Poniższą listę, warto potraktować jako punkt startowy.
Jak zdobyć wymarzoną pracę?
Zawsze najtrudniej jest zdobyć pierwszą pracę w IT. Potem w naturalny sposób, rozwijamy swoje kompetencje, nabywamy doświadczenia oraz kontaktów, które pomagają nam się rozwijać.
Co możemy zrobić, aby dostać pierwszą pracę, jako analityk danych / data scientist?
1. Zbudujmy podstawowe kompetencje
Python, bez wątpienia jest dobrą inwestycją i punktem startu. W momencie kiedy się go nauczymy, jesteśmy w bardzo dobrej pozycji aby zostać analitykiem danych, ale również pracować przy automatyzacji procesów biznesowych czy też zostać programistą Python.
Najlepszym sposobem nauki jest kurs Python w postaci ponad 100 lekcji wideo oraz dużej liczby ćwiczeń. Prowadzi nas od podstaw, do prawdziwych przykładów z firm. Możemy go znaleźć tutaj – Kurs Python
2. Przetwarzanie oraz wizualizacja danych
Następnie warto zapoznać się z przetwarzaniem oraz wizualizacją danych. Wiele z tych aspektów możemy zrobić za pomocą SQL oraz Excel, jednak znajomość Python Pandas oraz Python Seaborn pozwolą nam na automatyzację naszej pracy. Jest to również w zakresie wspomnianego kursu python.
3. Budujmy portfolio
Jeżeli szukamy naszej pierwszej pracy w IT, nie mamy doświadczenia, a tym samym, projektów którymi możemy się pochwalić.
Oprócz kompetencji, bardzo ważne jest przegotowanie portfolio, którym będziemy mogli się pochwalić. Mogą to być proste analizy, struktury baz danych, zastosowanie technologii big data i wiele, wiele innych rzeczy. Ważne jest aby zrozumieć, że na tym etapie, nie tyle liczy się złożoność naszych projektów co pokazanie, że jesteśmy – zorganizowani, potrafimy zastosować technologię w praktyce, jesteśmy zdeterminowani.
W ten sposób w pozytywny sposób wyróżnimy się na tle naszej konkurencji. Możemy opublikować artykuły, opisujące nasze doświadczenie na takich portalach jak linked in lub analityk.edu.pl, gdzie przy okazji, możemy dostać kilka cennych wskazówek odnośnie tego co i jak się uczymy, natomiast artykuły możemy publikować na LinkedIn oraz facebook jako nasze osiągnięcia w nowo poznanej dziedzinie.
Podsumowując
Analityk danych / data sciectist, to obiecująca i dobrze płatna ścieżka kariery. Aby rozpocząć naszą pierwszą pracę w tym zawodzie, musimy zdobyć kompetencje (co oczywiste), ale również zbudować portfolio. Jest to najczęściej lekceważona rzecz, a z drugiej strony coś, co nas bardzo wyróżnia na tle innych kandydatów.
Najlepszy sposób na rozpoczęcie kariery jako analityk danych jest zrobienie kursu Python oraz zdobycie końcowego certyfikatu.
Zachęcamy do bycia z analityk.edu.pl na bieżąco oraz wspólnego rozwoju.







