
Od czego zależy, że społeczeństwo danego państwa jest szczęśliwe? Na to pytanie próbuje odpowiedzieć, co roczne badanie – 'World Happiness’, w ramach którego, przeprowadza się ankiety w ponad 150 państwach. My, przyjrzymy się tym wynikom, i mamy nadzieję że zachęcimy do dalszych badań tego bardzo ciekawego zbioru.
Zaczniemy od zaimportowania podstawowych bibliotek, zbioru danych oraz zamiany nazw kolumn na polskie.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from plotly.offline import init_notebook_mode, iplot
import plotly.graph_objs as go
df = pd.read_csv('http://analityk.edu.pl/wp-content/uploads/2020/01/2019.csv')
df.columns = ['Ranking','Kraj','Szczęście', 'Zamożność Kraju', 'Wsparcie społeczne', 'Spodziewana długość życia w zdrowiu', 'Wolność podejmowania decyzji', 'Hojność', 'Poczucie korupcji']
df[:10]

Przy okazji widzimy, jakie 10 państw ma najbardziej zadowolone z życia społeczeństwo.
Polska zajmuje miejsce nr 40.
Dodatkowo, mamy informację o zamożności, wysokości wsparcia społecznego, spodziewanej długości życia, wolności, hojności, oraz poczucia korupcji. Mogli byśmy rozszerzyć ten zbiór o dane na temat klimatu, religii, dzietności, kultury itd, ale dzisiaj ograniczymy się tylko do pierwszych obserwacji.
Nanieśmy państwa, oraz ich poziom zadowolenia, na mapę świata, z użyciem biblioteki plotly.
Mapa świata
data = dict(type = 'choropleth',
locations = df['Kraj'],
locationmode = 'country names',
z = df['Szczęście'],
colorbar = {'title':'Skala szczęścia'})
layout = dict(title = 'Globalny Ranking Szczęścia',
geo = dict(showframe = False,
projection = {'type': 'natural earth'}))
choromap = go.Figure(data = [data], layout = layout)
iplot(choromap)
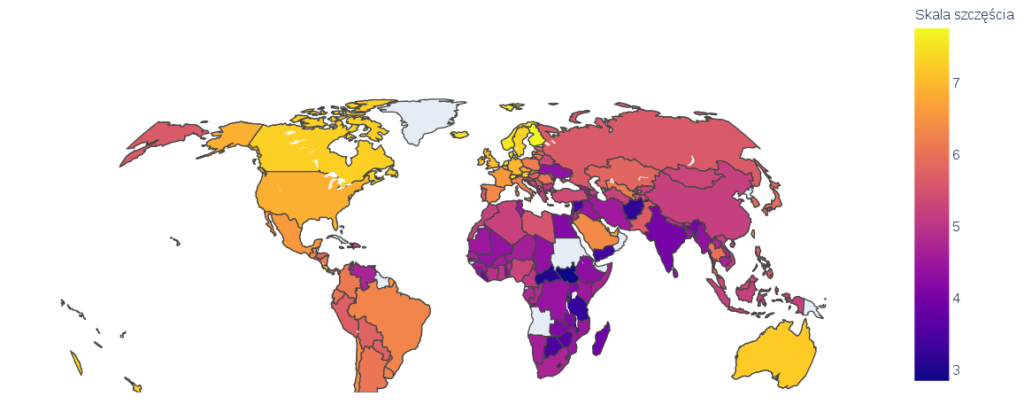
Na pierwszy rzut oka, widać, że Afryka oraz Azja, mają średnio mniejszy poziom zadowolenia mieszkańców. Zaraz po nich Ameryka południowa. Wysoki poziom, widać w Skandynawii, Australii oraz Ameryce północnej.
Korelacja zmiennych
Aby uzyskać szybki pogląd na to, które zmienne są ze sobą skorelowane, możemy użyć funkcji dostępnej w Pandas – corr(). W ten sposób uzyskamy również, informację, jakie z dostępnych zmiennych, wpływają na poziom szczęścia, w znaczący sposób. Dzięki Seaborn oraz funkcji heatmap(), zamienimy wyniki funkcji corr(), na reprezentację graficzną. Kolory jaśniejsze, świadczą o większej korelacji.
sns.heatmap( df.corr() ) plt.show()

Pierwsze wnioski:
- Szczęście, skorelowane jest silnie z zamożnością kraju, wsparciu społecznym oraz spodziewanej długości życia
- Powyższe zmienne, skorelowane są również, między sobą. Prawdopodobnie zamożność kraju, często niesie za sobą wyższe wsparcie państwa, lepszą opiekę zdrowotną, edukację itd. Co ma sens.
- Wolność, hojność oraz poczucie korupcji, również ma wpływ, jednak widocznie mniejszy.
Wolność podejmowania decyzji
Zobaczmy jaka jest relacja, pomiędzy wolnością podejmowania decyzji, a szczęściem mieszkańców, danego państwa.
sns.relplot(data=df,
x = "Wolność podejmowania decyzji",
y = "Szczęście",
aspect=2.5,
hue="Kraj",
legend=False)
plt.show()

Zależność, niewątpliwie jest, jednak nie tak duża jak można było się tego spodziewać. Widocznie, mamy państwa, w których mieszkańcy czują, że mają ograniczoną wolność, jednak są względnie zadowoleni.
Spójrzmy na kraje z poziomem wolności, poniżej 0.4 oraz poziomem szczęścia powyżej 5.5:
sns.relplot(data=df[(df['Szczęście']>5.5)&(df['Wolność podejmowania decyzji']<0.4)],
x = "Wolność podejmowania decyzji",
y = "Szczęście",
aspect=2.5,
hue="Kraj")
plt.show()

Jak widzimy, w krajach takich jak Pakistan, ludzie nie czują znaczącej wolności, jednak czują się szczęśliwi.
Zanim zostawimy kwestię wolności, zobaczmy jeszcze jak wygląda Polska:
df.loc[df['Kraj']=='Poland','Polska'] = 'Tak'
df.loc[df['Kraj']=='Poland','Polska'] = 'Nie'
sns.set_context('poster')
sns.relplot(data=df,
x = "Wolność podejmowania decyzji",
y = "Szczęście",
aspect=2.5,
hue="Polska")
plt.show()

Zamożność kraju, a szczeście
W dalszej kolejności zerknijmy na korelację zamożności (PKB) i szczęścia:
sns.lmplot(data=df,
x = 'Zamożność Kraju',
y = 'Szczęście',
aspect=2.5,
legend=False)
plt.show()

Korelacja jest o wiele bardziej widoczna niż w przypadku wolności podejmowania decyzji.
No cóż. Zamożność kraju, ma znaczący wpływ na szczęście mieszkańców, jednak nie jest to warunek konieczny. Widać obserwacje, poniżej normy, z wysokim poziomem zadowolenia.
data = dict(type = 'choropleth',
locations = df[(df['Szczęście']>5)&(df['Zamożność Kraju']<0.9)]['Kraj'],
locationmode = 'country names',
z = df['Szczęście'],
colorbar = {'title':'Skala szczęścia'})
layout = dict(title = 'Globalny Ranking Szczęścia',
geo = dict(showframe = False,
projection = {'type': 'natural earth'}))
choromap = go.Figure(data = [data], layout = layout)
iplot(choromap)


Podsumowując. Nawet w tej prostej analizie, widzimy znaczący wpływ zamożności kraju na szczęście mieszkańców, jednak widzimy również, że można posiadać rozsądny poziom szczęścia w sytuacjach mniej korzystnych.
To było tylko bardzo powierzchowne, spojrzenie na temat szczęścia. Jeżeli chcieli byśmy uzyskać bardziej miarodajne wyniki, powinniśmy nasz zbiór rozszerzyć o takie dane jak: klimat, kultura, religia, dzietność, itd.
Kody wykorzystywane w poniższych przykładach, dostępne są w repozytorium GitHUB, natomiast najświeższe wyniki badań – World Happiness – na tej stronie.







